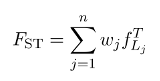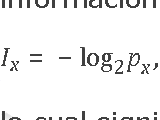by Alejandro Ochoa García
VIIIA
You need Javascript for this menu to work properly!
About me
Short bio, My career, interests, hobbies, life
I'm a well-rounded nerd
Ochoa Lab, at Duke University
Research in statistical genetics and computational biology
ochoalab.github.io
My Research Summary, in statistical and computational biology
I've studied evolution in DNA and proteins, and malaria.
CVRRICVLVM VITAE, my course of life
Yes, I've been a nerd since I was little.
Computational biology
metalcor, meta-analysis of correlated genetic association studies
Fixes inflation due to cryptic relatedness between studies
github.com
simfam, simulate and model family pedigrees with structured founders
Simulate random pedigrees, calculate kinship and admixture matrices, draw genotypes
github.com
simtrait, simulate complex traits from genotypes
Sets heritability accurately
github.com
genio, genetics input/output R functions
Handles plink and other formats
github.com
popkin, estimate population kinship and the generalized FST
Based on a model of arbitrary population structure
github.com
BNPSD, simulate genotypes from the BN-PSD admixture model
Based on the Balding-Nichols, Pritchard-Stephens-Donnelly, and generalized FST models
github.com
DomStratStats, stratified statistics for protein domains
Compute domain q-values and local FDRs, and tiered q-values
github.com
dPUC 2, Domain Prediction Using Context
Extend your Pfam predictions without loss of precision using domain context!
github.com
RandProt, generate high-order Markov random protein sequences
Fast implementation that captures subtleties of protein sequences
github.com
Domain predictions for the Apicomplexa, using DomStratStats
dPUC, Domain Prediction Using Context
Extend your Pfam predictions without loss of precision using domain context!
Music
Prison for Kids, my fan page
A wikipedia-style article of this amazing band
Prison for Kids Lyrics, and liner notes
Covers every release (albums, EPs, singles)
7
items
Prison for Kids Pictures - Live Shows, and other events
25
items
César's original soundtracks, from his short films
Excellent music back when he was only an amateur in college
29
items
Rock Concerts, In My Experience
A list of concerts that I've been to with a lot of information about them, including links to pictures.
32
items
Video and photography
MolBio Holiday Party Skits, at Princeton
The department has a holiday party with skits made by graduate students.
41
items
Cesar's short films, Inspired and filmed in Juarez
Directed and have music by César
21
items
Garcia, the family of my mother
It focuses mainly on my grandfather Baronio Garcia Montalvo, and in my childhood with the family.
18
items
ochoa
88
items
Sketches
4
items
Languages
Ochoa, the Family Name
A brief history of my paternal family name.
Quotes
A collection of quotes that I like a lot.
28
items
Mathematics
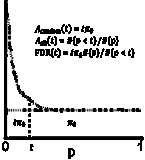
FDR and q-values, illustrating John Storey's method
Computing the false discovery rate is easier than you imagine!
Information theory, with intuitive examples on personal data
Names, birthdates, addresses, and other data.
Programming and computers
My website, a brief history
Knowing how to program, and wanting to post lots of pictures, have been the main driving forces behind my website.
VIIIA