![]()
![]() - ⇑
- ⇑

¡Necesitas Javascript para poder usar este menú adecuadamente!
¡Calcular la tasa de falso descubrimiento es más fácil de lo que imaginas!
¡Necesitas Javascript para poder usar este menú adecuadamente!
John Storey creó un método para convertir una lista de valores p en valores q, la diferencia siendo que el valor p mide la probabilidad cumulativa que una sola prueba sea asignada por un modelo nulo, mientras que el valor q mide la tasa de falso descubrimiento (FDR, por sus siglas en inglés; false discovery rate) que deberías incurrir si aceptas esta y cualquier prueba con un valor p más pequeño (y tal vez valores p más grandes, si el FDR mejora).
El problema principal que los valores q solucionan es el problema de pruebas múltiples de hipótesis. El problema es que un valor p, por mucho tiempo el estandard de las pruebas de hipótesis, no es confiable cuando se hacen muchas pruebas a la vez. Este es un problema común en biología, donde podrías preguntar si los cambios de expresión de genes son significantes a través de todo un genoma (más de 6,000 pruebas en la levadura, o 20,000 en humanos, correspondiendo al número de genes). Así que en una sola prueba rechazarías la hipótesis nula si el valor p es más pequeño que 0.05 (o sea que la hipótesis nula generó los datos observados o con mayor extremidad con 5% de probabilidad), pero con muchas pruebas, la probabilidad de que cualquiera de ellos sea falsa aumenta dramáticamente con el número de pruebas, así que usando un valor p máximo de 0.05 nos da que muchas más de 5% de las pruebas son falsas.
Vamos a asumir que lo que queremos en realidad es el valor del FDR, definido como la fracción de pruebas no rechazadas que son falsas. A primera aproximación, parece que corregir los valores p multiplicándolos por el número de pruebas debería aproximar mejor el FDR deseado, y de hecho eso es lo que la correción de Bonferroni hace. Desafortunadamente la correción se excede, en el sentido que pierdes demasiadas pruebas buenas. Se han desarrollado correcciones más avanzadas desde entonces (demasiadas para listar, mi objetivo no es ser comprensivo), pero actualmente el método de Storey parece ser el mejor en balancear la reducción de pruebas falsas y el aumento de pruebas verídicas.
Storey ha producido muchos grandes teoremas, y el objetivo de esta página no es reemplazarlos. En cambio, yo pensé complementar gráficamente la teoría para que cualquier persona interesada en implementar el procedimiento de valores q pudiera entended intuitivamente lo que están haciendo. Con seguiridad ignoro sutilezas en formulación, notación, etc; si desean las matemáticas completas vean (Storey, 2002). Yo prefiero pensar con imágenes.

Esto es dificil de explicar tan solo porque se supone que sea obvio. Imagina hacer muchas pruebas, y para cada una tienes la certeza (¿por construcción?) que la hipótesis nula es verídica. Crea un histograma con la lista de valores p que obtengas. ¿Qué proporción de ellos tienen p menor a t? ¡Deberían ser t!
Con datos reales esperarías ver fluctuaciones pequeñas (no mostradas en mi ilustración), por la naturaleza estocástica de los datos, pero la tendencia debería ser una distribución uniforme.
Es recomendado hacer esta prueba si puedes. Crea un conjunto donde esperes que la hipótesis nula sea verídica, y si no ves una distribución uniforme, puedes estar seguro que no estás calculando los valores p correctamente, o la hipótesis nula que escogiste es incorrecta. ¡Es crucial para este procedimiento que los valores p sean correctos!
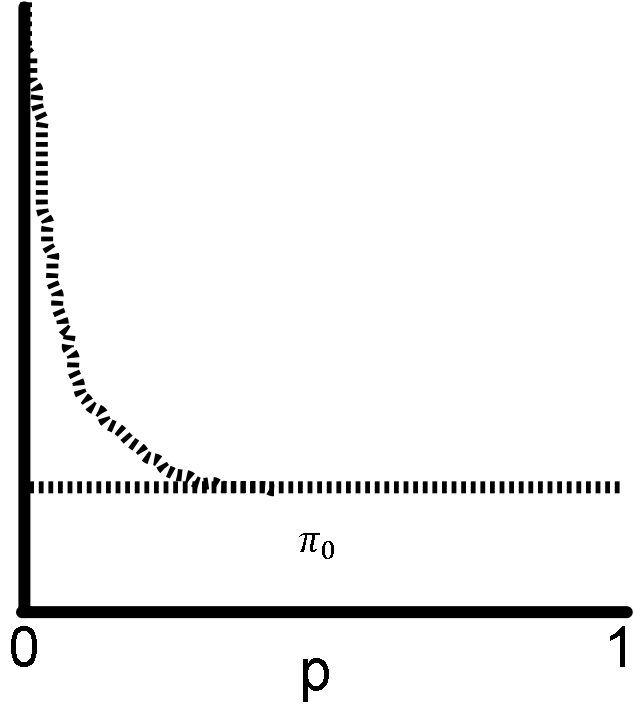
La suposición aquí es que entre tus pruebas, las que tienen los valores p más pequeños estan enriquecidos con pruebas en que la hipótesis nula es falsa.
Es importante que la distribución permanezca uniforme lejos de p=0 (con fluctuaciones pequeñas, otra vez no ilustradas), donde la mayoría de las pruebas se conforman a la hipótesis nula. De otra manera las mismas advertencias de antes aplican: o tus valores p no están calculados correctamente, o la hipótesis nula es incorrecta.
La clave en el procedimiento de Storey cae en estimar cuantas predicciones son falsas cerca de p=0. Imagina que tu distribución de valores p son una mezcla de dos distribuciones subyacentes, una en que la hipótesis nula es verdadera (uniforme), y la otra donde la hipótesis nula es falsa (el pico en cero).
El procedimiento necesita el valor de π0, la proporción de todas las pruebas en que la hipótesis nula es verídica. En mi figura, necesitas encontrar la altura de la linea que aproxima la distribución de valores p nulos. Es más facil estimar este valor caminando de p=1 hacia p=0. Mientras más te alejas de p=1, usas más datos para estimar π0, así que la varianza del estimado sería más baja, pero ariesgas incluir pruebas en que la hipótesis nula es falsa (y obtendrás un valor más grande del valor verdadero de π0).
Si crees que no puedes estimar π0 correctamente, puedes asignarle 1. Esto reducirá el poder del procedimiento de FDR, en el sentido que el FDR verdadero será más bajo que tu estimado, así que estarías perdiendo predicciones verdaderas. Pero usualmente π0 está muy cercano a 1 (si la mayoría de las pruebas satisfacen la hipótesis nula). De hecho, asignarle 1 reduce esta parte del procedimiento de Storey al procedimiento de Benjamini y Hochberg, el predecesor, y obviamente obtienes el mismo resultado de ambas maneras si π0 es suficientemente cercano a 1.
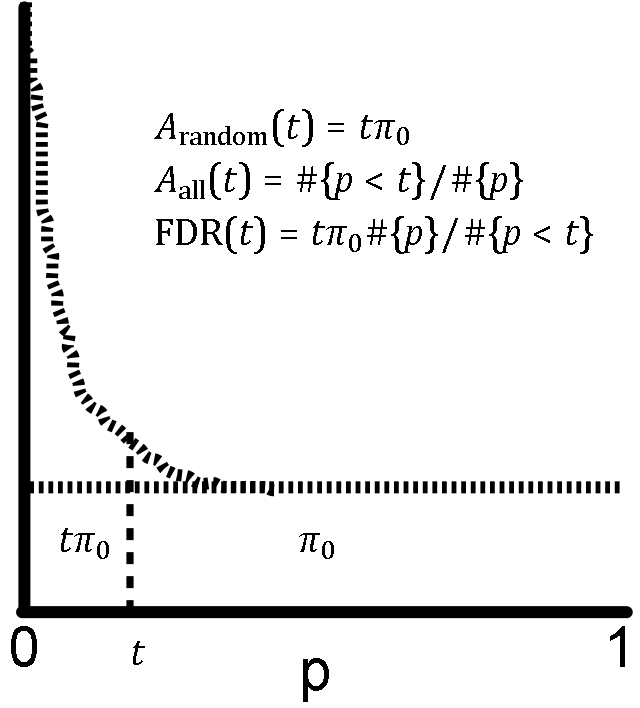
Aquí finalmente obtienes el FDR del problema de aceptar valores p bajo un límite.
Sea t el valor límite de tus valores p (cada prueba con p < t pasará). El FDR tiene dos partes. Asume que el area total ha sido normalizada a 1. El denominador es el area total con p <t, o el número de pruebas con p < t dividido por el numero total de pruebas. El numerador es el area estimada de pruebas falsas con p < t. Para reiterar nuestros resultados anteriores, el area total de pruebas falsas es π0, y la fracción de esa area con p < t, ya que es uniforme, es t⋅π0. La formula final, otra vez la fracción de predicciones que es falsa, está mostrada en la figura.
Así que todo esta bien si has escogido una t y quieres su FDR, pero generalmente se escoge el FDR primero, y deseas encontrar el límite t que tiene ese FDR. Aun mejor, ¿podremos analizar los datos sin tener que escoger un FDR en particular? Storey provee teoremas que muestran que puedes hacer lo siguiente sin nada raro.
Primero hay que tabular la función de t a FDR(t). Esencialmente caminamos de t=0 a t=1, y guardamos los valores FDR a como vamos. Esto se puede hacer muy eficientemente si codificas inteligentemente. Podríamos tratar el FDR(p) como el valor q de p, pero podemos mejorar la asignación un poco más. Usualmente FDR(p) aumenta si aumentas p (esto se puede ver en las figuras arriba), pero este no es siempre el caso (imagina lo que pasa si los datos reales fluctuan mucho). En ese caso, ¡el FDR(t) va a ser más pequeño para un límite t mayor que la p que estamos analizando! Tiene sentido usar ese FDR(t) como el valor q de p, ya que vamos a tener ¡más predicciones con un FDR menor al mismo tiempo!
Así que q(p) = mint; p<t FDR(t) es la definición final del valor q de p. De esta manera, los valores q son monotónicos con p. Para computar, si ya tenemos la tabla de t a FDR(t), podemos caminar al revés con t, de 1 al 0, para aplicar este "mínimo". Ahora, si quieres un FDR de 0.05, deberás aceptar todas las predicciones con q < 0.05. Y si en lugar de eso quieres un FDR de 0.01, usarías q < 0.01. ¡Es así de fácil!